Truy cập ID phần tử trong DOM dưới dạng biến cửa sổ / toàn cục
Trongnhững ngày đầu phát triển web, ID phần tử là một trong những điều đầu tiên tôi học được về cách thao túng các phần tử từ vùng đất JS. Với tham chiếu đến các yếu tố bằng ID của họ
<div id = "so_many"> Rất nhiều người phải suy nghĩ về </ div> <script> const so_many = document.getElemntByID ('so_many') </ script>
chúng ta có thể:
1: thay đổi html bên trong của phần tử (InternalHTML)
<div id = "so_many"> Rất nhiều người phải suy nghĩ về </ div> <script> const so_many = document.getElemntByID ('so_many') so_many.innerHTML = "Tôi đang bay không cánh" </ script>
2. thay đổi phong cách của phần tử
<div id = "so_many"> Rất nhiều người phải suy nghĩ về </ div> <script> const so_many = document.getElemntByID ('so_many') so_many.style.backgroundColor = "green" </ script>
3. nối một nút con vào phần tử
<div id = "so_many"> Rất nhiều người phải suy nghĩ về </ div> <script> const so_many = document.getElemntByID ('so_many') so_many.appendChild (document.createTextNode ('văn bản của tôi')) </ script>
4. loại bỏ phần tử khỏi nút trình duyệt
<div id = "so_many"> Rất nhiều người phải suy nghĩ về </ div> <script> const so_many = document.getElemntByID ('so_many') const textNode = document.createTextNode ('văn bản của tôi' ) so_many.appendChild .removeChild (textNode) </ script>
5. đính kèm và loại bỏ các trình lắng nghe sự kiện cho phần tử.
<div id = "so_many"> Rất nhiều người phải suy nghĩ về </ div> <script> const so_many = document.getElemntByID ('so_many') so_many.addEventListener ('tập trung', (evt) => { // .. code ở đây }) so_msny.removeEventListener ('tập trung') </ script>
* rất nhiều vv
Bây giờ mọi thứ sắp thay đổi thực sự.
ID phần tử trong đối tượng cửa sổ
Gần đây tôi đã biết rằng ID phần tử được lưu trữ dưới dạng biến toàn cục hoặc biến cửa sổ.
nó có nghĩa là gì?
Điều đó có nghĩa là nếu chúng ta tạo các phần tử gán cho chúng các thuộc tính id, thì các thuộc tính id có thể được truy cập thông qua đối tượng cửa sổ hoặc dưới dạng biến toàn cục.
Hãy nói rằng chúng ta có điều này:
<div id = "so_many"> Rất nhiều người nghĩ về </ div>
Đây là một yếu tố HTMLDivEuity có idthuộc tính giá trị so_many. Bây giờ, HTMLDivE bổ sung này có thể được truy cập thông qua so_manyđối tượng trong cửa sổ:
Vì có rất nhiều nhà phát triển phía máy khách, những người biết JavaScript và đã quen với cách ngôn ngữ đó hoạt động, nên họ rất dễ dàng đi đến Node.js và bắt đầu xây dựng các phụ trợ của riêng họ. Serverless có một loại tương tự về nó. Serverless rất dễ dàng để bắt đầu, bắt đầu xây dựng một dịch vụ đám mây và khởi động nó. Bạn không cần phải lo lắng về việc thiết lập và quản lý VM, phần mềm chống vi-rút, tường lửa, v.v. - tất cả những gì được thực hiện cho bạn bởi dịch vụ được quản lý.
Giờ đây, bạn có thể sử dụng các khung không có máy chủ để triển khai các hệ thống ở quy mô cho không chỉ các ứng dụng HTTP ở mặt trước mà cả các hệ thống phụ trợ thậm chí còn cách xa lĩnh vực chuyên môn của chúng. Đó là một điều rất dễ tiếp cận
Tác động của Serverless đối với hệ sinh thái Node.js
Bởi vì node.js là ngôn ngữ ngôi sao của serverless, chúng ta sẽ thấy serverless, vì nó trở nên phổ biến hơn, đưa nhiều người hơn vào hệ sinh thái của node.js. Tuy nhiên, có một vài vấn đề mà những người mới tham gia vào hệ sinh thái node.js phải đối phó. Gần đây, Node.js bắt đầu bỏ qua một số bài học mà chúng tôi đã học được từ không gian web. Chúng tôi trở nên quá thoải mái với thực tế là vì những thứ này sẽ hoạt động lâu trên máy chủ, nên không có vấn đề gì nếu các gói của chúng tôi rất lớn và chúng tôi tải mọi thứ trên thế giới và xử lý quá trình đó.
Ngoài ra, chúng ta có xu hướng suy nghĩ miễn là ứng dụng không chiếm dung lượng bộ nhớ sự kiện lớn, người quan tâm đến các tệp nhỏ mà chúng ta có và mọi thứ dọc theo các dòng đó. Node.js là tuyệt vời vì các trường hợp đơn giản, nó xuất hiện rất nhanh. Đối với các trường hợp bạn quyết định tiếp tục và nhập Lodash và mọi khung công tác khổng lồ mà bạn có thể nghĩ ra vào bộ nhớ, phải mất một thời gian để đọc những thứ đó từ đĩa. Dấu chân bộ nhớ sau đó có nghĩa là những người đang sử dụng các thư viện bên trong các hàm phải trả nhiều tiền hơn vì họ phải trả tiền cho dấu chân bộ nhớ đó để thực sự tồn tại.
Nếu bạn tải các thư viện khổng lồ vào bộ nhớ hơn bao giờ hết, bạn không phải trả tiền cho điều đó. Nếu tôi có thể chọn thư viện, một megabyte so với thư viện, là 30 megabyte, điều đó có thể có nghĩa là sự khác biệt lớn cho hóa đơn cuối tháng của tôi trong trường hợp không có máy chủ.
Nó thực sự trả tiền để suy nghĩ về cách chúng ta có thể đi trước và giảm những gì thực sự được tải. Rất nhiều điều có thể giúp với điều này.
Ví dụ kinh điển về tác động của Node.js
Azure Chức năng gói webpack mã của bạn tất cả cùng nhau. Nó không nhất thiết phải làm nhiều như vậy để giảm dấu chân bộ nhớ. Vì thế, bạn muốn tiếp tục và chạy Uglify trên đầu trang của kết quả đầu ra của gói web. Tuy nhiên, nó làm giảm thời gian tải.
Ai đó từ Microsoft Azure đã kiểm tra gói với bốn mô-đun nút lớn nhất mà anh ta có thể tìm thấy. Anh ta đang cố gắng hiểu tác động của serverless đối với Node.js. Anh ta đặt chúng vào một chức năng và đo nó trên một chiếc i7 bằng ổ SSD. Đó là một hệ thống nhanh như chớp nhưng phải mất khoảng hai giây để chức năng đó xuất hiện lần đầu tiên.
Sau đó, chúng tôi đã làm cho Node.js đọc tất cả những thứ đó vào bộ nhớ. Khi anh ta đóng gói nó, mất khoảng một trăm mili giây - một cải tiến khổng lồ.
Khi bạn đang chạy trong serverless, sẽ mất nhiều thời gian hơn để tải các mô-đun đó vào bộ nhớ. Nhiều nhà cung cấp bán hàng thực sự có giới hạn về số lượng nội dung bạn thực sự có thể đưa lên đó ngay từ đầu. Điều quan trọng là phải suy nghĩ khi chúng ta viết các gói này, đặc biệt nếu chúng ta muốn các gói này hoạt động trong máy chủ, chúng ta cần nghĩ những thứ đó sẽ làm gì.
Đọc tài liệu trước khi mã hóa
Trong một trường hợp, một ứng dụng socket.io tại một công ty cơ sở dữ liệu chính, đã bắt đầu tiêu thụ quá nhiều ổ cắm. Các nhà phát triển Node.js làm việc trên ứng dụng nhận ra chức năng họ viết đang đến đó, liên tục sử dụng nó, mở các socket nhưng không đóng chúng. Tất nhiên, họ đã lạm dụng thư viện. Họ đã không đọc tài liệu đúng cách. Họ không sử dụng chức năng theo quy định nhưng họ đã sử dụng nó theo cách mà họ cảm thấy tự nhiên khi sử dụng chức năng đó - bên trong chức năng của họ.
Cách giải quyết nhanh khi viết gói có thể gây hại khi sử dụng trong máy chủ, nhà phát triển phải viết cảnh báo. Hướng dẫn cách tạo một cá thể đơn lẻ của nó bên ngoài hàm để nó nằm trong bộ nhớ của chúng. Nếu chúng ta nói về ví dụ socket.io ở trên, hướng dẫn cách viết mã cho nó để đóng socket trước khi các chức năng hoàn thành sẽ có ích rất nhiều.
Những cảnh báo và hướng dẫn này có thể giúp một cách lâu dài để đảm bảo rằng bất kỳ ai mã hóa Node.js trên serverless đều không cảm thấy xa lạ. Nó sẽ trả tiền để đảm bảo mọi người thành công theo cách đó.
Node.js và serverless thực sự đã đi rất xa và thực sự tốt vì tính chất nguồn mở, mạnh mẽ của mọi thứ và việc truy cập vào các phần của hệ thống dễ dàng như thế nào.
Rủi ro tiềm tàng
Vì việc triển khai dịch vụ ngày nay rất cụ thể của nhà cung cấp, nên có một số rủi ro ở đó. Vì vậy, đó là điều đáng để ghi nhớ. Có những người ngoài kia đang suy nghĩ về các cách để giải quyết một số vấn đề này.
Mặc dù các nhà cung cấp đang xây dựng một triển khai cụ thể chủ yếu được thiết kế để chạy trên nền tảng đám mây của họ, họ có thể biến nó thành nguồn mở. Họ nên cố gắng xây dựng nó theo cách nó giống một hệ thống di động hơn một chút. Họ nên đảm bảo rằng bạn không cảm thấy như mình bị khóa mặc dù nó được xây dựng để chạy thực sự tốt trên nền tảng đám mây của họ.
Những nỗ lực nên theo hướng mà các nhà cung cấp đang cố gắng đảm bảo rằng ít nhất họ xây dựng nó trong nguồn mở và cuối cùng hoạt động theo hướng mà ngay cả nền tảng mở.
Tương lai là đây!
Khi bạn đang suy nghĩ về việc cố gắng triển khai các dịch vụ ra đám mây, hãy xem xét đường dẫn không có máy chủ bất cứ nhà cung cấp nào bạn cảm thấy phù hợp với mình. Đó là tất cả về việc cố gắng cải thiện sự nhanh nhẹn mà bạn có thể triển khai và xây dựng các dịch vụ mà bạn có thể tin tưởng sẽ hoạt động tốt ở quy mô. Node.js có thể xây dựng nhiều hơn với serverless và bạn đã ở trong tình trạng tốt. Nếu biết ngôn ngữ lựa chọn trên nền tảng này - Node.js, thì bạn đã đi trước trò chơi. Serverless đã lợi dụng thực tế là Node.js và JavaScript đã có cộng đồng mở, lớn, tuyệt vời này.
In this post, we’ll learn how to use Node.js and friends to perform a quick and effective web-scraping for single-page applications. This can help us gather and use valuable data which isn’t always available via APIs. Let’s dive in.
What is web scraping?
Web scraping is a technique used to extract data from websites using a script. Web scraping is the way to automate the laborious work of copying data from various websites.
Web Scraping is generally performed in the cases when the desirable websites don’t expose the API for fetching the data. Some common web scraping scenarios are:
Scraping emails from various websites for sales leads.
Scraping news headlines from news websites.
Scraping product’s data from E-Commerce websites.
Why do we need web scraping when e-commerce websites expose the API (Product Advertising APIs) for fetching/collecting product’s data?
E-Commerce websites only expose some of their product’s data to be fetched through APIs therefore, web scraping is the more effective way to collect the maximum product’s data.
Product comparison sites generally do web scraping. Even Google Search Engine does crawling and scraping to index the search results.
What will we need?
Getting started with web scraping is easy and it is divided into two simple parts-
Tip: Don’t duplicate common code. Use tools like Bit to organize, share and discover components across apps- to build faster. Take a look.
Setup
Our setup is pretty simple. We create a new folder and run this command inside that folder to create a package.json file. Let’s cook the recipe to make our food delicious.
npm init -y
Before we start cooking, let’s collect the ingredients for our recipe. Add Axios and Cheerio from npm as our dependencies.
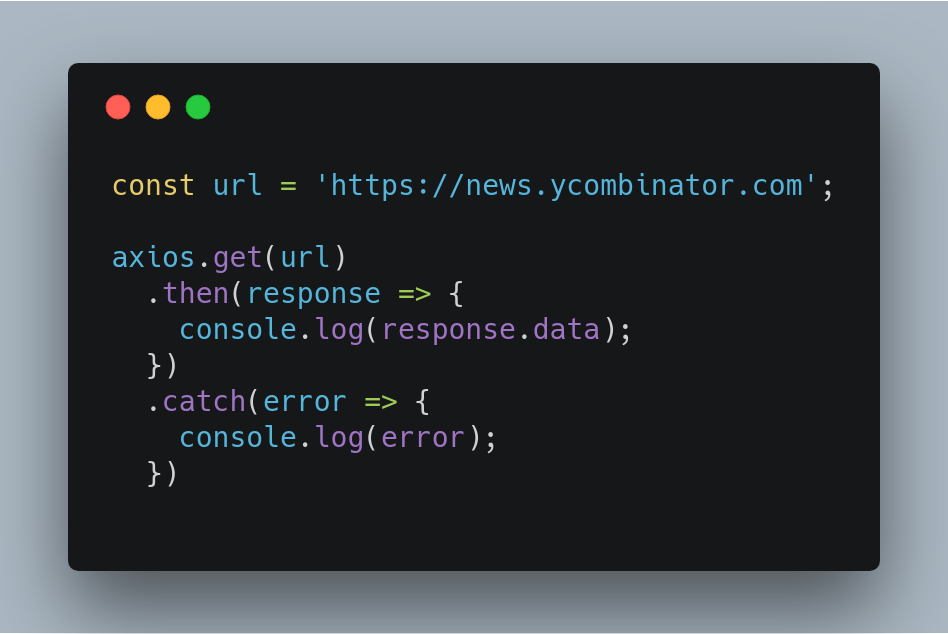
We are done with collecting the ingredients for our food, let’s start with the cooking. We are scraping data from the HackerNews website for which we need to make an HTTP request to get the website’s content. That’s where axios come into action.
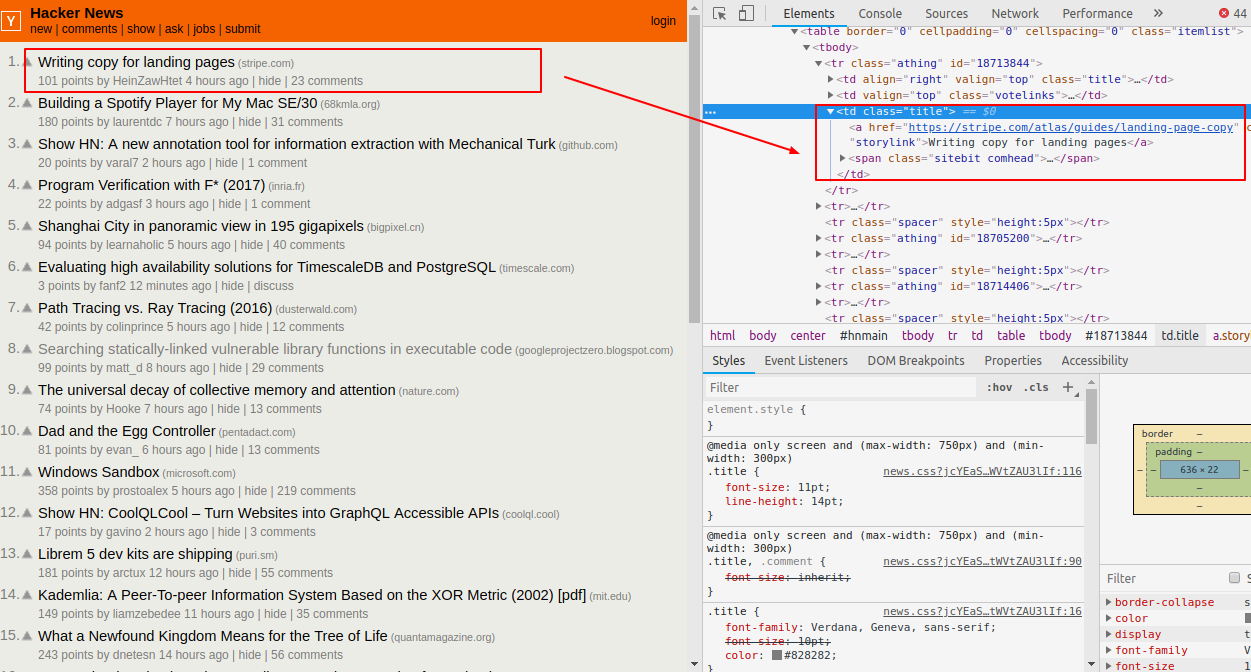
We are getting similar HTML content which we get while making a request from Chrome or any browser. Now we need some help of Chrome Developer Tools to search through the HTML of a web page and select the required data. You can learn more about the Chrome DevTools from here.
We want to scrape the News heading and its associated links. You can view the HTML of the webpage by right-clicking anywhere on the webpage and selecting “Inspect”.
Parsing HTML with Cheerio.js
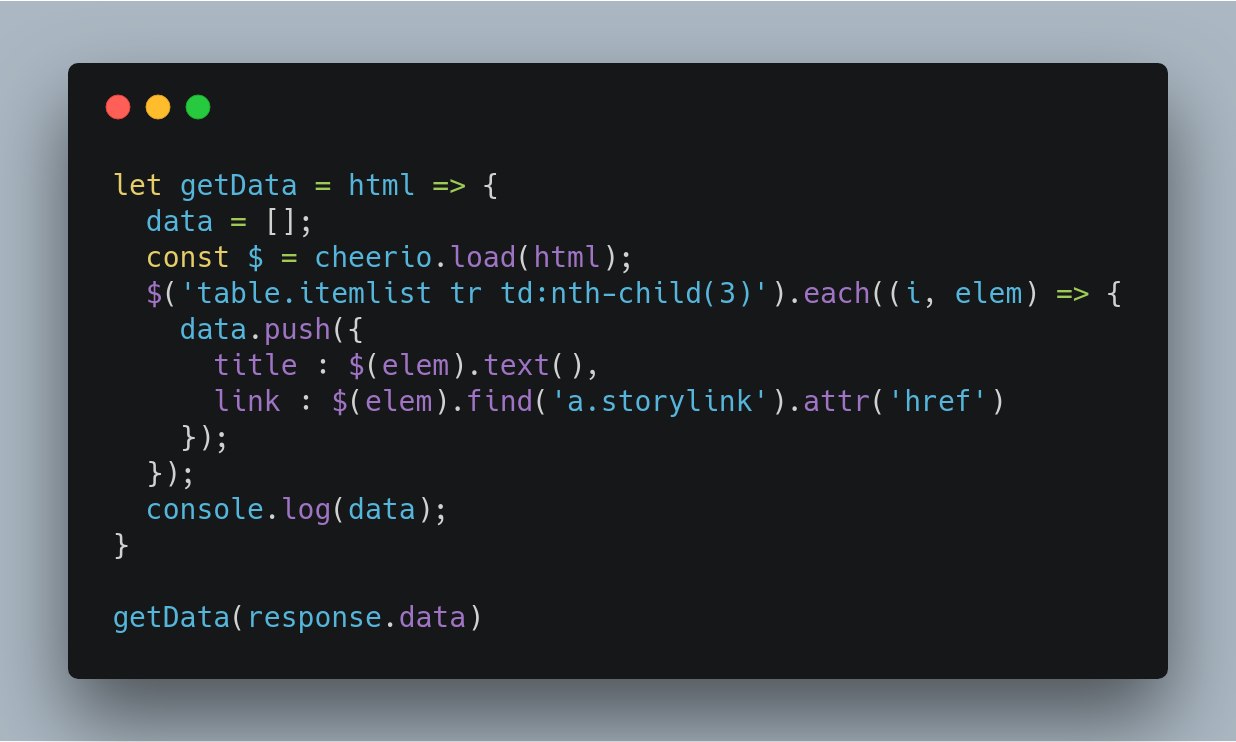
Cheerio is the jQuery for Node.js, we use selectors to select tags of an HTML document. The selector syntax was borrowed from jQuery. Using Chrome DevTools, we need to find selector for news headlines and its link. Let’s add some spices to our food.
First, we need to load in the HTML. This step in jQuery is implicit since jQuery operates on the one, baked-in DOM. With Cheerio, we need to pass in the HTML document. After loading the HTML, we iterate all the occurrences of the table row to scrape each and every news on the page.
The Output will look like —
[
{
title: 'Malaysia seeks $7.5B in reparations from Goldman Sachs (reuters.com)',
link: 'https://www.reuters.com/article/us-malaysia-politics-1mdb-goldman/malaysia-seeks-7-5-billion-in-reparations-from-goldman-sachs-ft-idUSKCN1OK0GU'
},
{
title: 'The World Through the Eyes of the US (pudding.cool)',
link: 'https://pudding.cool/2018/12/countries/'
},
.
.
.
]
Now we have an array of JavaScript Object containing the title and links of the news from the HackerNews website. In this way, we can scrape the data from various large number of websites. So, our food is prepared and looks delicious too.
Conclusion
In this article, we first understood what is web scraping and how we can use it for automating various operations of collecting data from various websites.
Many websites are using Single Page Application (SPA) architecture to generate content dynamically on their websites using JavaScript. We can get the response from the initial HTTP request and can’t execute the javascript for rendering dynamic content using axios and other similar npm packages like request. Hence, we can only scrape data from static websites.
I will soon write an article on “how to scrape data from dynamic websites”. Meanwhile, Cook your own recipes!!
Feel free to comment and ask me anything. You can follow me on Twitter and Medium. Thanks for reading!
Làm cách nào để chuyển đổi các trang Facebook công cộng sang RSS?
Ngày 12 tháng 6 năm 2018
RSS đã xuất hiện trở lại trên sân khấu chính gần đây vì tin tức giả mạo và các vụ bê bối truyền thông xã hội, tuy nhiên nó chưa bao giờ là công cụ vô giá để các doanh nghiệp và tổ chức nghiên cứu và theo dõi thông tin trực tuyến, đặc biệt là từ các kênh truyền thông xã hội như Facebook .
Chúng tôi sẽ đề cập đến ba dịch vụ ở đây, Inoreader là một tùy chọn trả phí, Zapier miễn phí nhưng chỉ hoạt động cho các trang Facebook của riêng bạn, trong khi FetchRSS cung cấp một cấp miễn phí để tạo 5 nguồn cấp dữ liệu trang công khai tuyệt vời trên Facebook.
Thông tin nhanh về Inoreader - Trình đọc RSS hoặc trình tổng hợp nội dung giúp mọi người theo dõi, sắp xếp và giám sát tất cả trong một trang web mà không cần một thuật toán cung cấp cho bạn một nguồn cấp tin tức. Nếu bạn muốn theo dõi các nguồn cấp dữ liệu Instagram dưới dạng RSS , hãy xem điều này.
Bạn có thể là một người theo dõi tự do theo dõi các trang Facebook cụ thể để lấy cảm hứng hoặc người quản lý nội dung, người cần tìm kiếm nội dung tốt nhất cho ngành công nghiệp của mình. Bất kể nhu cầu của bạn là gì, đây là một số cách để chuyển đổi nguồn cấp dữ liệu trang công khai của Facebook thành nguồn cấp RSS luôn mới, đẹp.
NB * : CÁC CÔNG CỤ DANH SÁCH DƯỚI ĐÂY LÀM VIỆC KHI CHÚNG TÔI KIỂM TRA, CHÚNG TÔI KHÔNG ĐẢM BẢO RATNG CÁC CÔNG CỤ NÀY VẪN LÀM VIỆC KHI BẠN ĐỌC
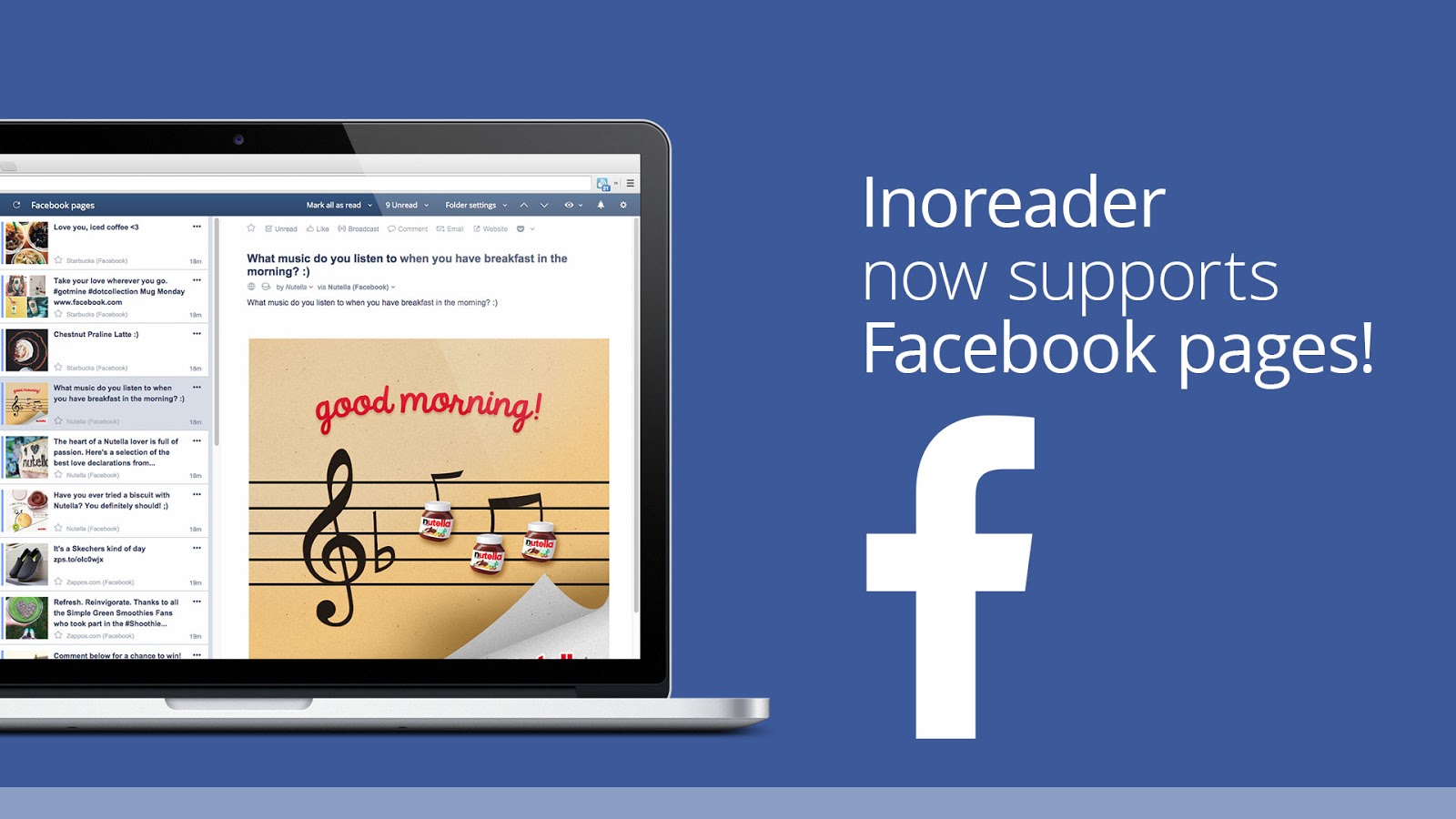
Inoreader tự động chuyển đổi các trang Facebook thành nguồn cấp RSS cho bạn, chỉ cần nhập URL trang Facebook và ứng dụng sẽ nhận ra đó là đăng ký hợp lệ.
Nếu bạn chưa từng làm điều đó trước đây, ứng dụng sẽ yêu cầu bạn cung cấp quyền truy cập mã thông báo truy cập Facebook và bạn đã sẵn sàng!
Thêm các trang Facebook công khai trực tiếp vào Inoreader. Nâng cấp trên gói của chúng tôi PLUS PLUS cho phép 30 trang Facebook công cộng và gói PRO PRO CHUYÊN có giá trị lên tới 100.
Hãy cẩn thận : Sử dụng Inoreader để theo dõi các trang Facebook là thiết thực và hiệu quả về chi phí, nhưng có những cảnh báo. Do Facebook hạn chế nghiêm trọng quyền sử dụng API của họ, chúng tôi buộc phải cung cấp hình ảnh chất lượng thấp hơn và đôi khi không có hình ảnh nào trong các bài đăng. Đây là lý do tại sao tính năng này hữu ích nhất để theo dõi số lượng lớn bài đăng và trang, áp dụng các quy tắc và bộ lọc nhất định cho chúng hoặc tích cực lắng nghe các đề cập từ khóa cụ thể. Cũng khá hữu ích cho việc tuyển chọn nếu trang chủ yếu là một trình tổng hợp nội dung và đăng các liên kết của bên thứ ba.
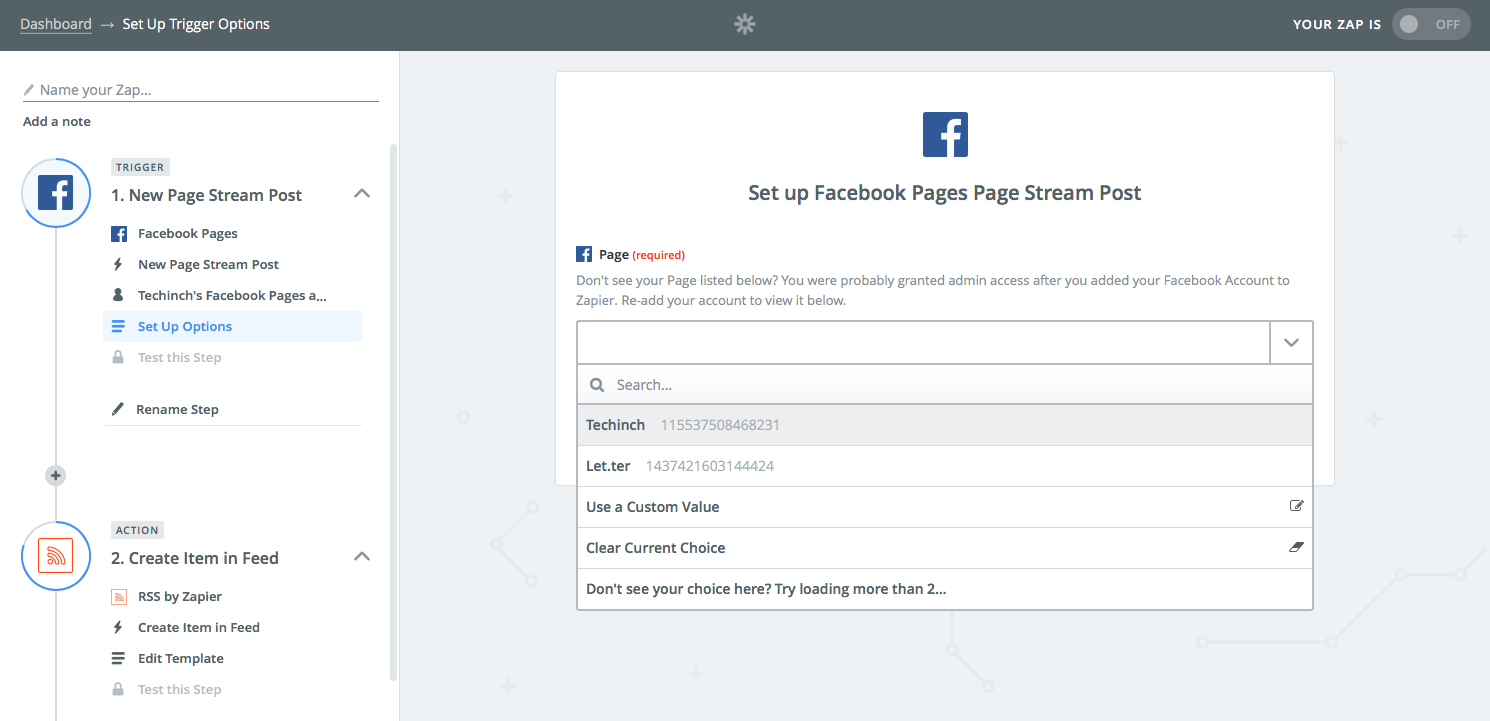
2. Zier
Chuyển đổi các trang Facebook thành RSS với Zapier . Họ đưa ra một hướng dẫn khá chi tiết về cách kết nối và sử dụng các số liệu của họ để đạt được điều này.
Hãy cẩn thận * : Thật không may, Zapier có thể được sử dụng để CHỈ theo dõi các trang Facebook của riêng bạn nơi bạn có quyền truy cập quản trị viên. Đối với bất kỳ trang Facebook công khai nào khác, bạn sẽ cần đăng ký cao cấp Inoreader.
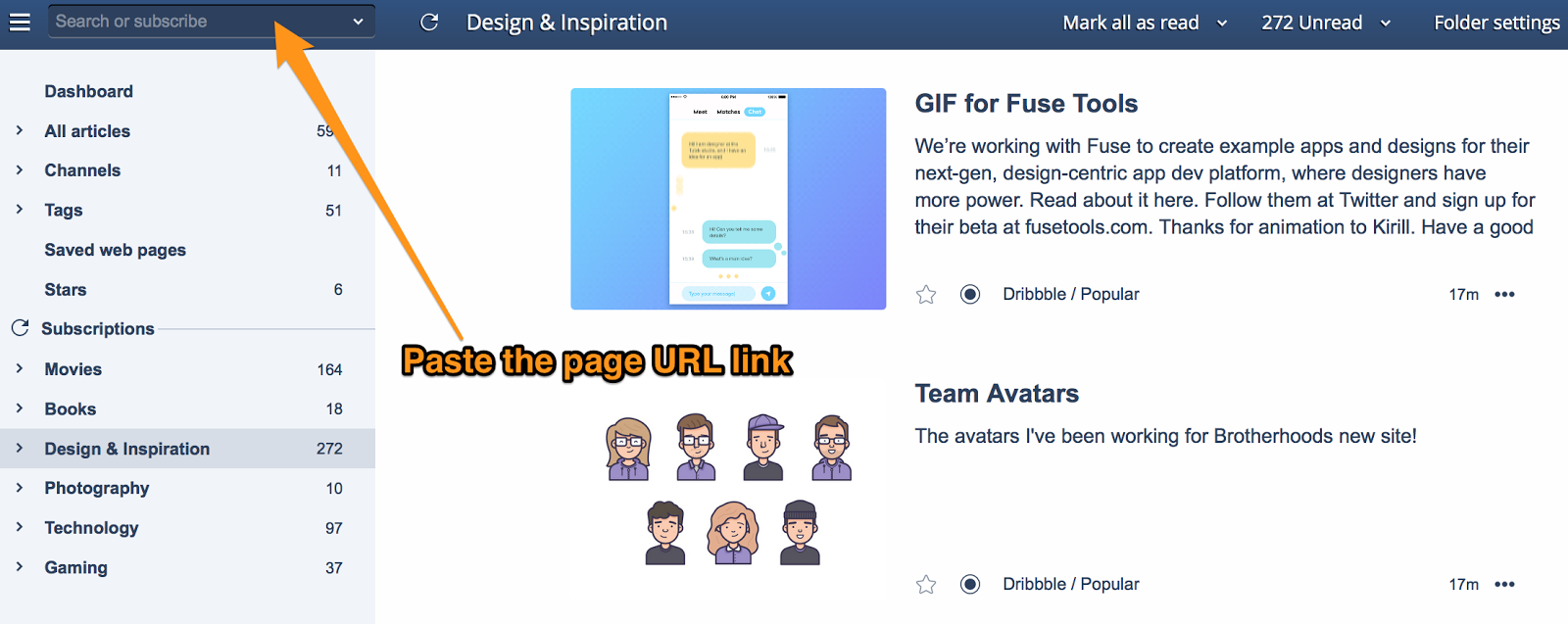
Nhập URL trang Facebook và bạn sẽ nhận được một URL RSS phù hợp mà bạn có thể đặt bên trong bất kỳ trình đọc RSS nào, rõ ràng chúng tôi khuyên bạn nên đặt nó trong Inoreader.
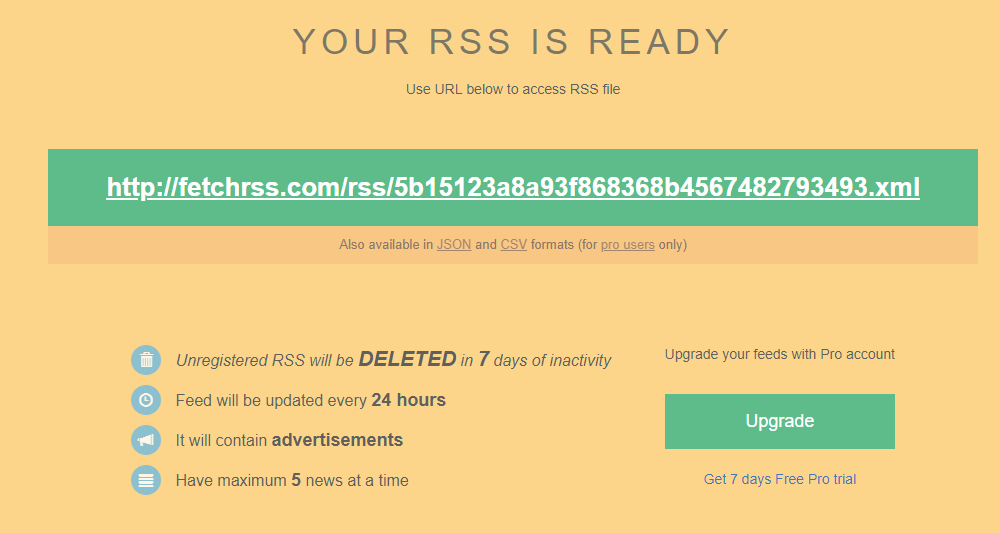
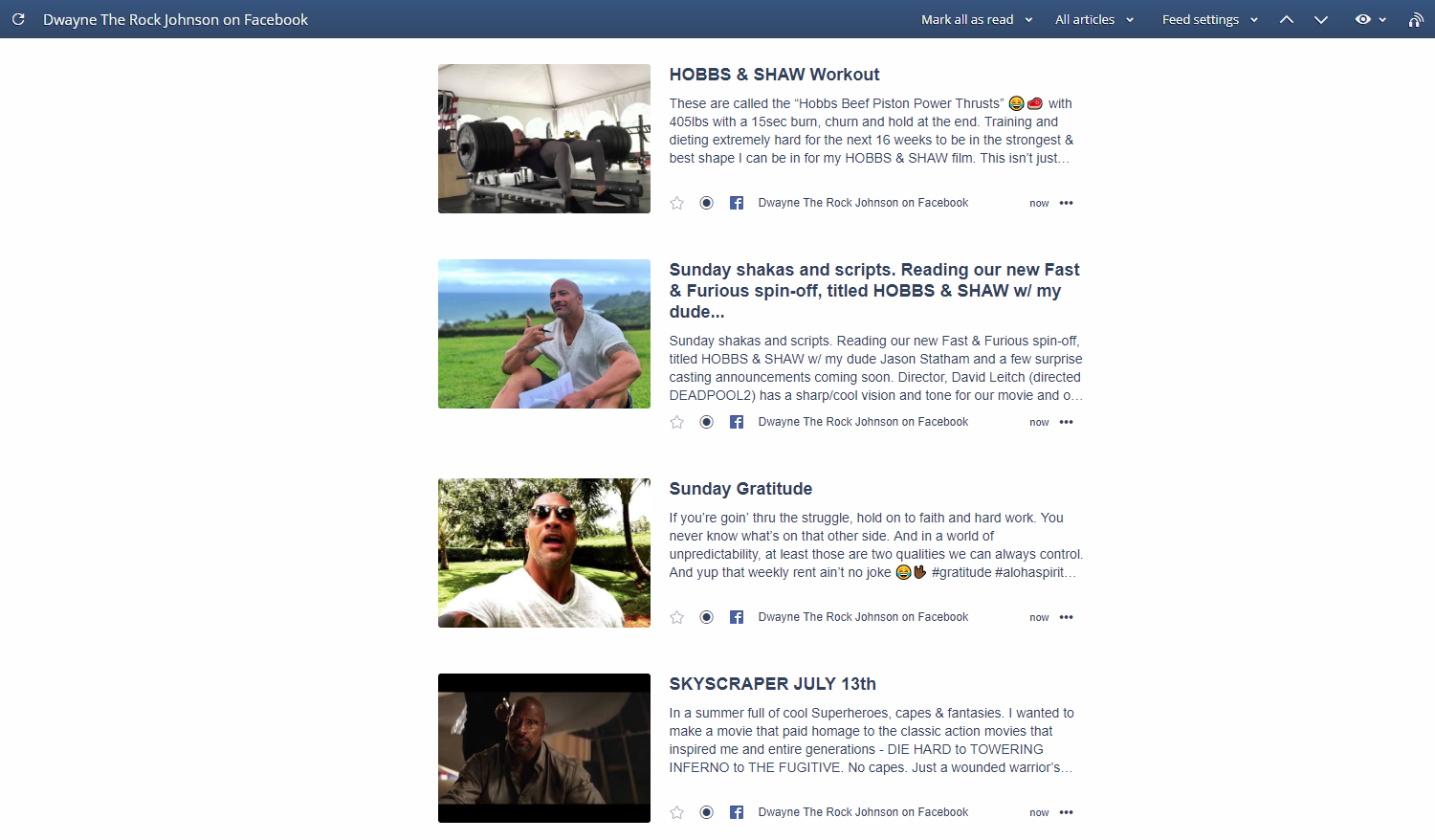
Một dịch vụ tuyệt vời với cấp MIỄN PHÍ, FetchRSS cung cấp hình ảnh chất lượng cao tuyệt vời và nội dung bài đăng hoàn chỉnh. Đây là cách một trong những nguồn cấp dữ liệu của họ trông như thế nào khi được thêm vào bên trong Inoreader!
Có nhiều lựa chọn hơn chúng ta đã bỏ lỡ? Xin vui lòng cho chúng tôi biết trong các ý kiến.